
Das Datenmodell wird im folgenden anhand eines einfachen Beispiels erläutert.
Das Datenmodell besteht aus dem Reference Node Space und dem Model Space . Im Reference Node Space liegt der für den Zugriff auf alle Modelle entscheidende Reference Node . An ihn sind alle Modelle über den Subreference Node angebunden. Im Model Space befinden sich sämtliche Modelle. Im Model Space sind drei Ebenen erkennbar, die Metametamodellebene , die Metamodellebene und die Instanzmodellebene . Es werden Modelle aller Ebenen an den Subreference Node angebunden. Im Beispiel sind dies ecore.ecore, library.ecore und library.xmi. Sämtliche Beziehungen zwischen den Elementen werden durch eine RELATIONSHIP abgebildet. Beziehungen zwischen Elementen einer Ebene werden über die CONTAINS Beziehung realisiert. Eine Sonderstellung nimmt EClass ein, da es sich selbst erklärt und daher keine eingehende INSTANCE Beziehung besitzt. Ausprägungen enstehen durch die INSTANCE Beziehung und überschreiten die Ebenengrenzen.
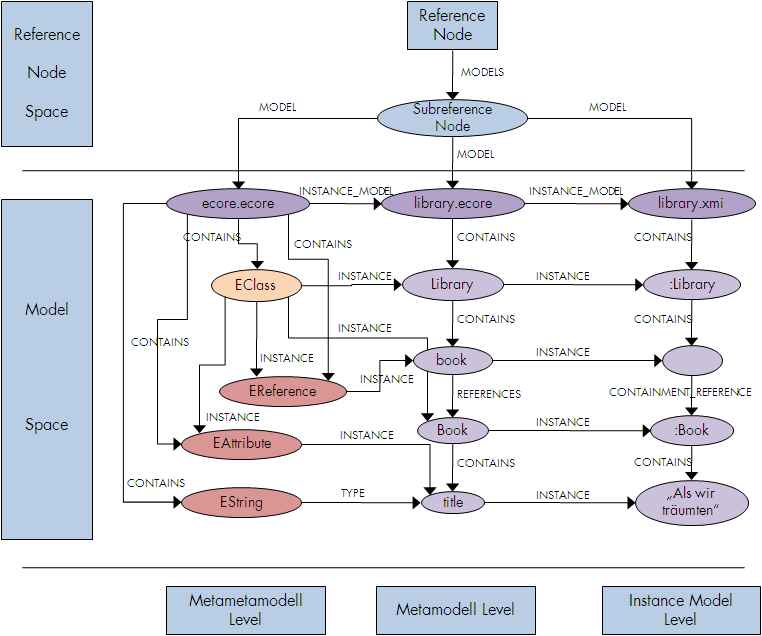
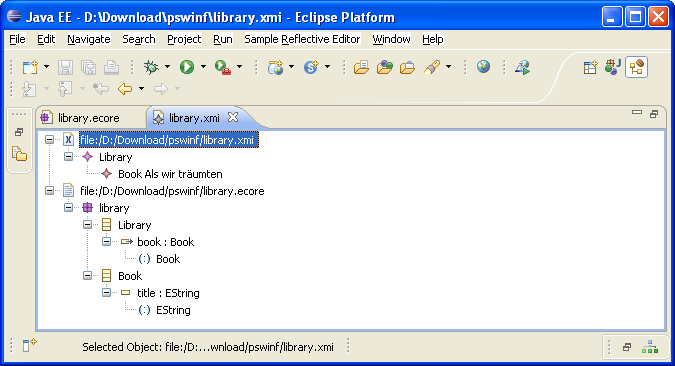
Zur Verdeutlichung des Datenmodells ist das Instanzmodell library.xmi abgebildet. Es enthält sein Metamodell library.ecore.
Für die Kommunikation zwischen Client und Server muss ein Netzwerkprotokoll gewählt werden, das geeignet ist, die auf dem Client serialisierten Daten zum Server und ggf. zurück zu übertragen. Mehrere Möglichkeiten bieten sich, die sich jedoch durch verschiedene Kriterien unterscheiden.
Das API-Level bestimmt den Grad an Abstraktion. Eine niedrige API bietet Methode, den Datenstrom selbst aufzubauen und auf die Datenübertragung stark Einfluss zu nehmen. Eine hohe API erwartet ein zu übertragendes Objekt und kapselt die technischen Aspekte der darunter liegenden Schichten und Interna.
Der Serialisierungsmechanismus muss aus einem Objekt einen serialisierbaren Datenstrom erzeugen und der Deserialisierer muss diesen Vorgang umkehren können. Die Zuordnung der zu übertragenen Datenstrukturen und Umwandlungsrichtlinien zu Java-Klassen ist die Typbindung.
Typbindung kann manuell erstellt werden, in dem Konvertierer für die Datentypen erstellt werden. Ein anderer Weg ist die Generierung der Konvertierer durch einen Codegenerator (z.B. Axis2 WSDL2Java). Eine dritte Möglichkeit besteht in der dynamischen Konvertierung durch einen konfigurierbaren Konvertierer (z.B. Castor).
Wird ein Objekt serialisiert, so kann es, muss aber nicht zwangsweise in ein Objekt der Ursprungsklasse deserialisiert werden. Der Typ des deserialisierten Objektes muss nicht einmal typkompatibel mit dem Typ des serialisierten Objektes sein. Sind die Typen identisch, so spricht man von Typsymmetrie zwischen Client und Server, andererseits von Typasymmetrie. Typasymmetrie unterscheidet sich noch dahingehend, ob eine typkompatible Asymmetrie (Typen sind durch Vererbung verwandt, mindestens einer der beiden Typen (-> asymmetrisch) kann durch Casting in den anderen Typ gewandelt werden) besteht oder nicht (Typen sind nicht durch Vererbung verwandt und lassen sich deshalb nicht durch Casting ineinander umwandeln).
Die Kommunikation sollte auf einem API-Level erfolgen, dass so hoch wie möglich ist. Da jedoch mit der Höhe auch die Möglichkeiten der Einflussnahme auf die Kommunikation schwinden, ist der begrenzende Faktor die Verfügbarkeit der notwendigen Einflussmöglichkeiten.
Die Typbindung sollte nicht per Hand implementiert werden, da dies bei Änderung der Struktur der Daten eine Anpassung des Codes nach sich zieht. Auch die Generierung von zu übersetzendem Code stellt nur eine schlechte Lösung dar, da bei Strukturänderungen ebenfalls eine Neuübersetzung - wenn auch keine Anpassung - des Codes nötig wird. Die sauberste Lösung stellt die dynamische (und damit konfigurierbare) Konvertierung dar.
Das zu wählende Protokoll sollte nicht zu Typsymmetrie verpflichten. Es sollte möglich sein, dass serialisierter und deserialisierter Typ frei wählbar sind (natürlich müssen beide Typen die Informationen speichern können, die Schnittstellen und erst recht die Implementierungen sollte aber unabhängig von einander frei wählbar sein). Wäre dies nicht der Fall, wäre das Datenformat nicht interoperabel.
Zur Zeit stehen zwei Techniken zu Auswahl, um die Datenkommunikation zu realisieren. Auf der einen Seite ist dies RMI, auf der anderen Seite Webservices. Neben des höheren Levels von WS gegenüber RMI besteht ein großer Vorteil bei WS in der nicht vorhandenen Verpflichtung zur Typsymmetrie. Während bei RMI der Typ auf der Seite des Clients und des Server identisch sein muss, ist dies bei WS nicht der Fall.
Unser Bedarf besteht somit an einer WS-Lösung. Es besteht keine Typsymmetriepflicht. Bei der Auswahl der Typbindung muss zwischen dynamischer und statischer (generierter) Typbindung entschieden werden. Aus Gründen der Einfachheit und Performance sollte unsere Entscheidung zu Gunsten der statischen Typbindung fallen.
RMI mag geeignet sein, die Kommunikation zu stellen, weist aber eine vollkommene Typsymmetrie auf. Damit funktionieren Client und Server nur dann, wenn sie ausschließlich die selben Versionen der Klassen und Bibliotheken verwenden. Weichen die Versionen voneinander ab, lassen sich serialisierte Daten nicht mehr deserialisieren. Damit tritt in einer verteilten Umgebung das Problem der Versionskopplung auf: Ändert sich die Version der Klassen auf dem Server, müssen alle Clients aktualisiert werden. Dieses Szenario ist in einer verteilten Umgebung jedoch nicht realisierbar. RMI ist als Kommunikationsprotokoll somit nicht geeignet.